
Ciao. Oggi ti presento seaborn, un pacchetto molto importante che lavora su matplotlib e lo rende più aperto, per produrre grafici più eleganti e personalizzabili. Come ti avevo illustrato in questo mio precedente articolo in cui ho introdotto R, Python ha delle limitazioni nel gestire i grafici statistici con immediatezza e versatilità estetica.
In pratica seaborn consente di fare degli sforzi in questa direzione.
Ma prima di cominciare facciamo un passo indietro. e torniamo alla questione dei seed.
Il metodo seed di numpy.random
Qui ti avevo parlato dell’importanza di seminare i generatori di numeri casuali. per fare questo si usa il metodo seed di numpy.random e gli si passa come argomento un numero intero. Per esempio:
np.random.seed(1)
rappresenta una chiave che va invocata ogni qual volta si vuole ottenere la stessa estrazione di valori casuali. Il valore 1 rappresenta solo una scelta arbitraria.
I creatori di seaborn hanno scelto di abbellire il codice usando un criterio che serve a ricordare ogni volta quale chiave si sta passando al metodo seed.
Per esempio, nel tutorial di seaborn vediamo che gli autori hanno scelto la stringa “distributions”. Questa viene inserita nella seguente istruzione:
np.random.seed(sum(map(ord, "distributions")))
L’argomento del metodo seed è una sequenza (sum(map(ord, “distributions”))) che restituisce il numero int 1427. Vediamo di analizzare in dettaglio questo meccanismo.
sum, map e ord sono 3 oggetti nativi di Python:
In[1]: type(sum), type(map), type(ord) Out[1]: (builtin_function_or_method, type, builtin_function_or_method)
secondo il docstring di map (che puoi richiamare digitando “map?”):
map(func, *iterables) --> map object Make an iterator that computes the function using arguments from each of the iterables. Stops when the shortest iterable is exhausted.
mentre il docstring di ord (indovina: “ord?” ;)):
Return the Unicode code point for a one-character string.
In pratica se invochiamo ord su una stringa come ‘ciao’ viene sollevata una eccezione. Allora possiamo reiterare ord su ogni singolo carattere di ‘ciao’ e per farlo dobbiamo usare map:
In[2]: map(ord, 'ciao') Out[2]: <map at 0x5b5d450>
Abbiamo creato un iteratore. Nota bene che questo è il comportamento secondo python 3.6. Se avessi usato python 2.7 come kernel avrei ottenuto automaticamente una lista. Per visualizzarla dobbiamo usare il metodo list:
In[3]: list(map(ord, 'ciao')) Out[3]: [99, 105, 97, 111]
con il metodo builtin sum al posto di list otteniamo la somma degli elementi di tipo int della lista, ovvero 412.
"axis_grids"
seaborn
Come al solito per l’installazione attiva l’ambiente conda in cui vuoi essere operativo con seaborn e installalo con conda install seaborn.
Questa è la pagina dove puoi trovare le informazioni relative al progetto seaborn.
La prima cosa da fare in un nuovo notebook è importare tutti i pacchetti di cui abbiamo bisogno
import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Se vogliamo fare pratica sui dataset, ora abbiamo bisogno… di un dataset! Gli sviluppatori di seaborn ne hanno messo a disposizione una serie in chiaro per metterci nelle condizioni di fare pratica. Vai sul sito https://github.com/mwaskom/seaborn-data :
Hai visto che questa repository è piena di file csv che puoi liberamente usare per fare pratica.
Nel sito ufficiale del progetto seaborn seaborn.pydata.org trovi tutto il necessario per procedere con gli esempi.

Quando cerchiamo di fornire una rappresentazione grafica di un dataset, in alcuni casi possiamo aver bisogno di fare un regressione lineare. Ti rimando sulla definizione che ne da la pagina di wikipedia per richiamare questi concetti.
Facendo clic sul primo riquadro trovi un esempio di codice che riguarda il primo file csv: anscombe.csv. In questa pagina dell’esempio trovi
import seaborn as sns #il pacchetto viene importato sns.set(style="ticks") #lo stile ticks viene impostato per il progetto df = sns.load_dataset("anscombe") #il file anscombe.csv è caricato sns.lmplot(x="x", y="y", col="dataset", hue="dataset", data=df, col_wrap=2, ci=None, palette="muted", size=4, scatter_kws={"s": 50, "alpha": 1}) #4 grafici risultanti vengono visualizzati
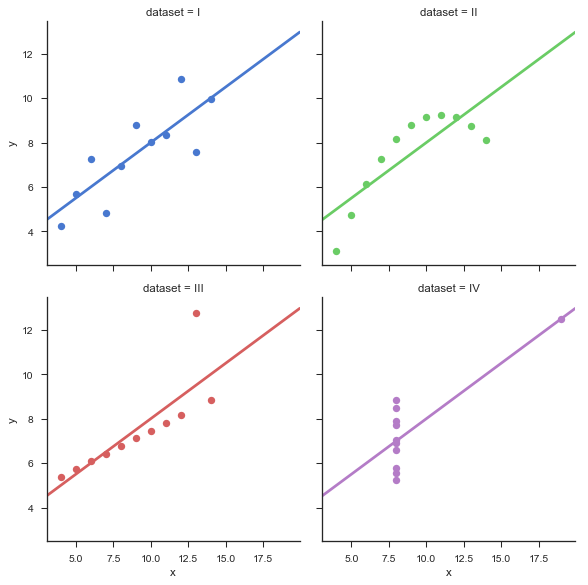
L’interesse del dataset anscombe giace nel voler sottolineare come 4 diverse distribuzioni univariate con differenti proprietà siano associate esattamente alla stessa retta di regressione lineare. In parole povere le quattro rette che approssimano questi dati hanno la stessa intercetta e lo stesso coefficiente angolare. In realtà, con un occhio più esperto si capisce che i dati del dataset II non andrebbero analizzati con una regressione lineare, bensì almeno con una regressione quadratica. Invece nel dataset IV i datapoint sarebbero approssimati da tutt’altra retta se non fosse per un unico punto. In statistica, quest’ultimo viene chiamato outlier o, in italiano, valore anomalo.
Per oggi mi fermo qua. Tornerò su seaborn nel mio prossimo articolo e lo legherò ai dataframe di pandas.
